Using Machine Learning to Create New Melodies
BY BRANNON DORSEY
Music is storytelling. Melodies are memories. We create them from the musical experiences, conscious and unconscious, that we are exposed to throughout our lifetimes. Passed down through time in a kind of oral tradition, the music that we make today carries with it embeddings of the culture and people of times long past. Musical motifs are not the product of an individual artist, but rather a reinterpretation of the musical ideas that have been presented to them, for them to reinterpret and pass along to others. In this way, writing music can be thought of as less of a process of authorship and instead a practice of remix.
We’ve been working with algorithms that can learn from hundreds of thousands of past songs, and use this learned knowledge to synthesize new musicAt Branger_Briz, we’ve recently been experimenting with these ideas of remix and new ways of approaching authorship through the lens of machine learning using memory networks. We’ve been working with algorithms that can learn from hundreds of thousands of past songs, and use this learned knowledge to synthesize new music. Inspired by recent works in the field of machine learning, especially projects like Magenta that seek to include the involvement of artists and musicians, we’ve created our first algorithm that can learn to create music by example. You can listen to a short sample from it below.
We've created a tool that others can use and learn from Midi-rnn is a tool we’ve created that allows you to generate monophonic melodies with machine learning using a basic LSTM RNN, a model architecture designed to work with sequences. Inspired by the Magenta project’s first model, we decided to create midi-rnn from scratch using Keras, with the goal of having a baseline music-generation model to compare the rest of our ongoing research against. Going through these motions has been incredibly helpful for us as we explore the landscapes of computer music, machine learning, and scientific computing in general. Additionally, we’ve now created a tool that others can use and learn from.
Of the many machine learning techniques that could be applied to music generation with MIDI, midi-rnn approaches the task in a relatively simple and naive way. Like much of the research and prior work that precedes it, midi-rnn excels at learning to (re)produce succinct melodic bits that are of interest, but fails to create music with overarching or consistent long-form structure.
Midi-rnn is an implementation of a Recurrent Neural Network (RNN) that uses Long-Short Term Memory (LSTM) units. RNNs architectures have been proven to work very well at learning to model sequential data. Their popularity and use has risen greatly since Andrej Karpathy’s blog post entitled "The Unreasonable Effectiveness of Recurrent Neural Networks" in the summer of 2015. In this post, Karpathy provides source code for a model he titles char-rnn, which learns to represent text at a character-level by example. Midi-rnn is an almost identical model/algorithm to char-rnn, only it uses MIDI data as input and output instead of text characters.
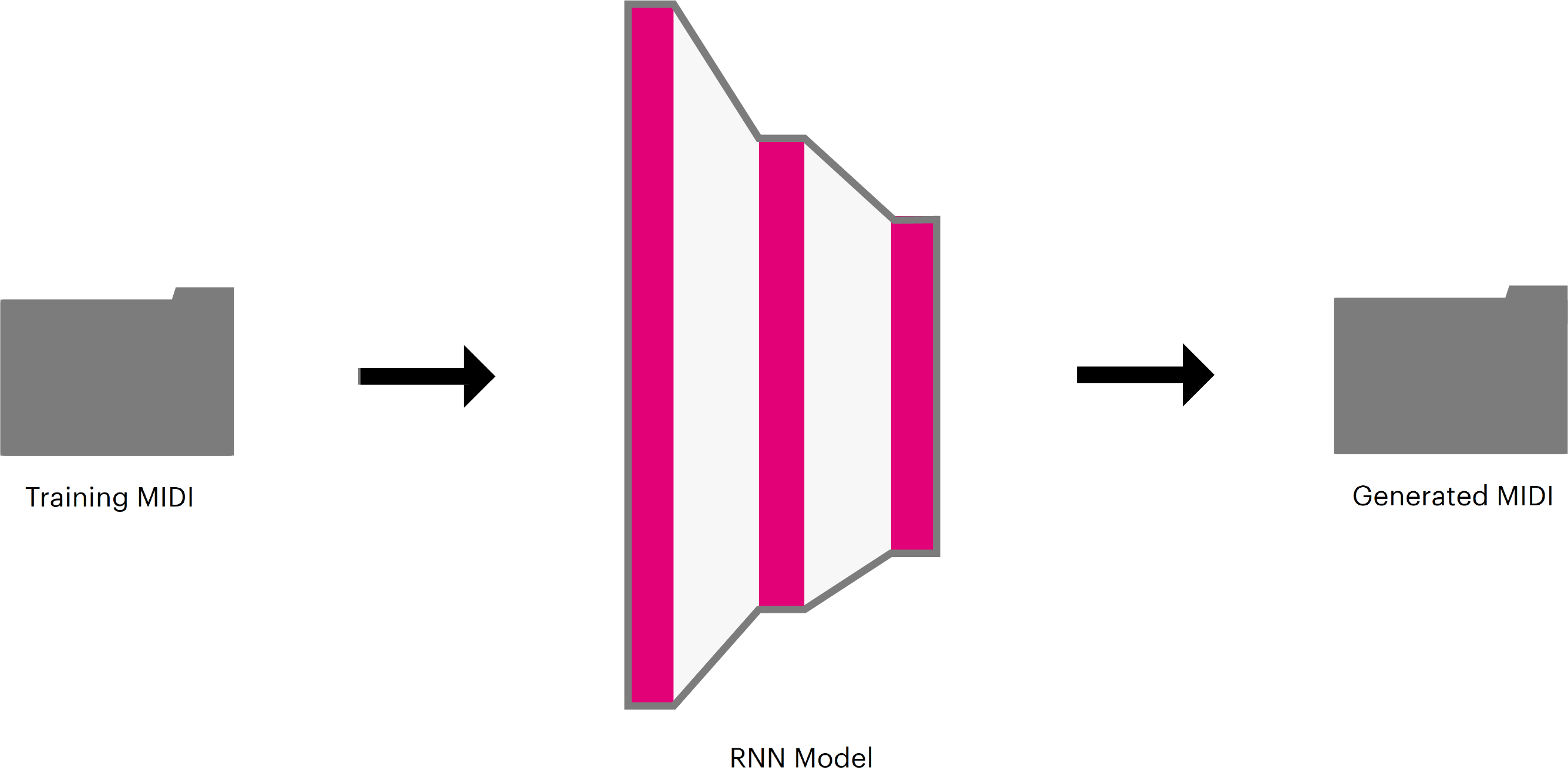
At a high level, our machine learning pipeline can be thought of as process that takes a folder of MIDI files, trains an RNN model using those MIDI, and then later uses that model to generate an arbitrary number of new MIDI files.
The section that follows is a somewhat technical breakdown of how Midi-rnn works. If you would prefer to get started using midi-rnn right away, feel free to jump down to the instructions section. We've also included some example melodies that we generated using midi-rnn at the bottom of this post.
Midi-rnn Algorithm Breakdown
Midi-rnn works like this: You take a folder of MIDI songs that you would like to use to train your model. For each MIDI song, midi-rnn filters out all non-monophonic tracks and discards them. It then breaks down the remaining tracks into a series of fixed-width windows that represent the song as sections of note events of 16th-note durations, including rests. Each window, X, contains n such events where n is the window size. The below image uses a window size of 10 (n = 10). Each collection of events X is paired with the value of the event at n + 1, which we call y. The value of y is the note that follows the fixed-width note sequence X in the MIDI track. We slide our window across each of our MIDI tracks collecting X, y pairs to create our data set. Each y is used as our training label for the sequence of notes X in our supervised learning task.

MIDI is a standard representation for recording and storing information about musical events. It symbolizes all (Western) musical notes C-2 - G8, as one of 128 values (0-127). In order to use this data as input to midi-rnn, we transform each note from this integer format into an encoding known as "one-hot" encoding before feeding it into our model for training. One-hot encoding represents categorical data as a binary representation with a "bit-depth" equal to the number of classes, in our case 129, where all bit values are set to zero except for the index of the category being represented by the encoding, which is set to one. Representing data in this way ensures that our model doesn’t mistakenly learn that the arbitrarily assigned magnitude of a MIDI note value carries meaning. MIDI note 120 in is not greater than MIDI note 20, both are used simply categorical labels.
Before we train our model we must first split our collection of one-hot encoded X, y pairs into two groups, the training set and the validation set. The training set is used to train our model, while the validation data is held out and used to evaluate our model’s performance on data that it has never seen before. We use our training data to update and continually improve our model, however, when we show our model the validation data, we do not update the model. Instead, we simply see how well it performs at predicting the next note in each sequence from our validation set to better understand how well the model is learning to generalize the patterns that it is extracting from the training data. How much data you hold out for validation depends on the size and quality of your training data, but an 80%/20% training/validation is generally a good split to start with.
Our RNN is a network made up one input layer with length(X) * length(X1) units (neurons), one or more hidden layers with an arbitrary number of units, and one output layer with length(X1) units. length(X) is the value of our window size (n), say 10, which is the number of previous notes we will feed into our model at each timestep in order to predict the next note. length(X1) is the number of categorical classes we are representing, or the "bit-depth" of our one-hot encoding, which is 129 in our case (0-127 + 1 for rest events).
Our model is trained by iteratively feeding it input data X and computing the result of the output layer through a process of matrix multiplications, summations, and non-linear activation functions. We pass the values of the output layer over a softmax function resulting in a probability distribution that gives us the likelihood of each categorical class (0-128) being the next event in the event sequence that was provided as input X. Because we have labels y, we know what the true next event value is, so we can compare our model’s prediction with the true event category from our MIDI sequence. Because we have a probability distribution as output, we can quantify how correct/incorrect our model’s prediction is at each training step, and update our model to minimize our prediction error. In practice we feed our model batches of multiple X, y training pairs before updating it by backpropagating the sum of our error across the batch through the network. This method of optimization is called Mini-batch Stochastic Gradient Descent (SGD). SGD, and its many variants, are the optimization algorithms used for most modern deep processes.
Once we’ve trained our model we freeze it and use it to generate new melodies Once we’ve trained our model by iteratively applying our training process until our error values stop decreasing, we freeze our model and use it to generate new melodies! During generation, we can’t use existing values for all inputs X, because the song we are creating doesn’t exist yet. We solve this using a clever method that incorporates the output of the model from one timestep as a component as part of the input to the next timestep. We begin generation by feeding our model a single window X from an existing piece of music. This initial input is called the seed, or sometimes prime, and it is used to get our sequence generation process started. The first note event category predicted as the output of the first step of our model during generation is added to the input sequence X, and the first note event category in <X is removed. Given a window size of 10, the first 9 notes now belong to our seed, and the most recent note was generated by our model. This <X sequence is now fed back into the model for time step two, after which the first value in the input sequence X is removed and the predicted note is appended to X like last time. After 10 steps, our input sequence X is comprised entirely of note event categories generated by our model. The model can now run indefinitely using its own note event predictions as the input sequence to generate new melodies in this way.
Using Midi-rnn
You can use midi-rnn to generate your own new melodies! The following content assumes basic understanding of command line/terminal usage and a MacOS or linux operating system. For more information about installing and using midi-rnn see the GitHub repository.
# open a terminal and clone the midi-rnn repo
git clone https://github.com/brannondorsey/midi-rnn.git
# navigate into the cloned directory
cd midi-rnn
# Install the dependencies. You may need to prepend sudo to
# this command if you get an error
pip install requirements.txt
Once you’ve installed midi-rnn and its necessary dependencies you can train a model using the sample midi tracks included with the repository.
python train.py --data_dir data/midi
After a brief moment, you should see continuous output that looks like this:
1/154000 (epoch 0), train_loss = 3.759, time/batch = 0.117 2/154000 (epoch 0), train_loss = 3.203, time/batch = 0.118 3/154000 (epoch 0), train_loss = 3.000, time/batch = 0.115 4/154000 (epoch 0), train_loss = 2.951, time/batch = 0.116 5/154000 (epoch 0), train_loss = 2.892, time/batch = 0.118 6/154000 (epoch 0), train_loss = 2.876, time/batch = 0.118 7/154000 (epoch 0), train_loss = 2.836, time/batch = 0.118 8/154000 (epoch 0), train_loss = 2.859, time/batch = 0.117 9/154000 (epoch 0), train_loss = 2.829, time/batch = 0.117
You can use Tensorboard to view your training error over time. In another terminal opened to the midi-rnn directory run the following:
tensorboard --logdir experiments/
Navigate your web browser to http://localhost:6006 to view your models training error in real time. Once you see that it has converged, or plateaued, your model likely won’t improve and can actually get worse (this is called overfitting). You can stop the training pressing CTRL+C from the terminal window that is running the training process. You are now ready to generate new MIDI tracks using sample.py.
python sample.py --data_dir data/midi --experiment_dir experiments/01
By default, this creates 10 MIDI files using and saves them to to experiments/01/generated.
Once you’ve gone through the motions of training your model on the stock midi files, head over to the midi-rnn project README for more info about supported command-line arguments and custom training parameters.
Midi-rnn Example Melodies
Below you will find some select audio snippets that we pulled from melodies generated using midi-rnn. All files were trained using the same ~100 MIDI files from the Lakh MIDI Dataset.
Have some thoughts to share? Join the public conversation about this post on Twitter, or send us@brangerbriz.com an email, we'd love to hear what you think!