Muse AI Supercuts
social marketingIn their latest music video for the single "Dig down" the British rock band Muse pays homage to remix culture on the Internet - and passes control to computers.
The Task
The band Muse and their label Warner Music UK were interested in producing a series of algorithmically generated music videos to promote the band’s latest single Dig Down. Given the track’s political undertones they wanted custom software which would leverage contemporary AI (Machine Learning) technology to generate daily supercuts where each word in the song would be voiced by a person of note.
This aesthetic has been achieved previously using manual editing processes but only recently has technology advanced to the point that we're able to create this programmatically. The video series was released as a daily video for a month. To manually generate these videos daily with topical subject matter would have been impossible just a few short years ago.
The Challenge
The project’s timeline was incredibly tight given the scope, which meant we had to be particularly resourceful. Rather than collecting data to train AI models from scratch, we would need to leverage pre-trained models and, though we specialize in producing custom code, we knew we would have to be strategic about leveraging pre-existing open-source tools for various parts of the project. We designed a software pipeline that would not only be capable of producing the supercuts on schedule but also be modular and flexible enough to accommodate quick changes and the unanticipated challenges that often arise with heavy data-driven projects like this one.
The Solution
With projects like this where so much of the final aesthetic would be determined by chance (in this case, the quality of random videos uploaded to the Internet) it’s hard to tell what the final look, sound and feel is going to be until you do it. Our first drafts made clear some of the challenges we would have to address, from developing special tools to efficiently vet the data being fed into the system to meticulously tweaking the algorithm such that it cut clips together which both matched the original rhythm of the song while allowing any given clip the proper time to playthrough.
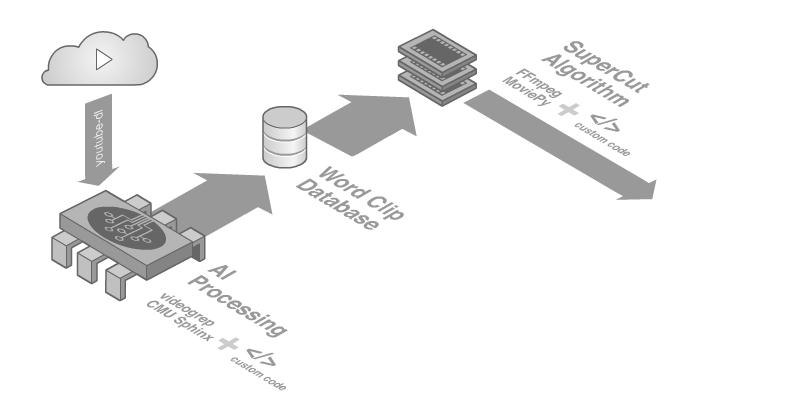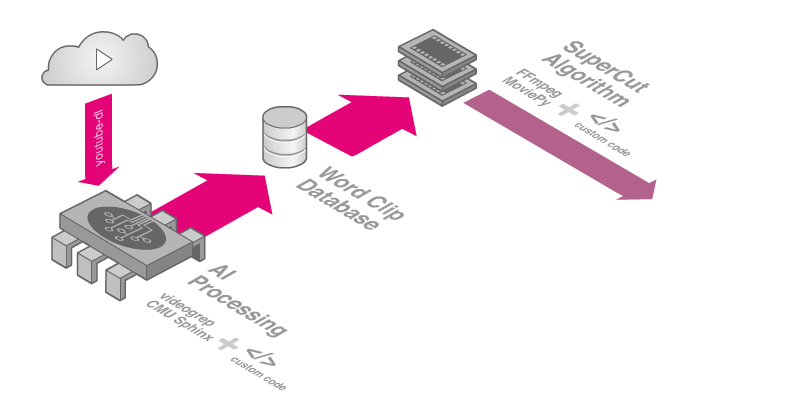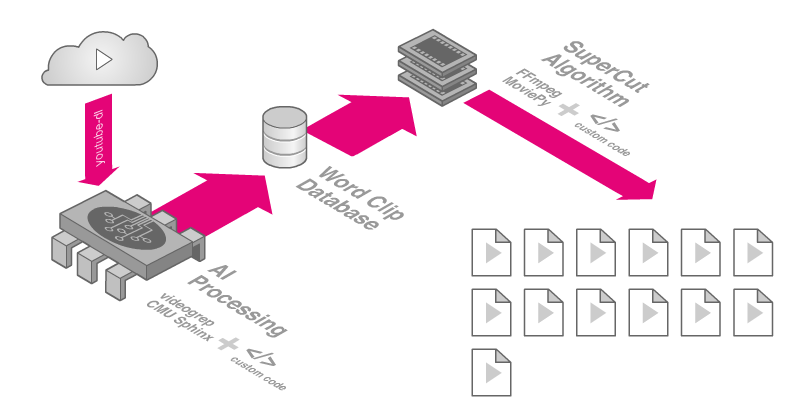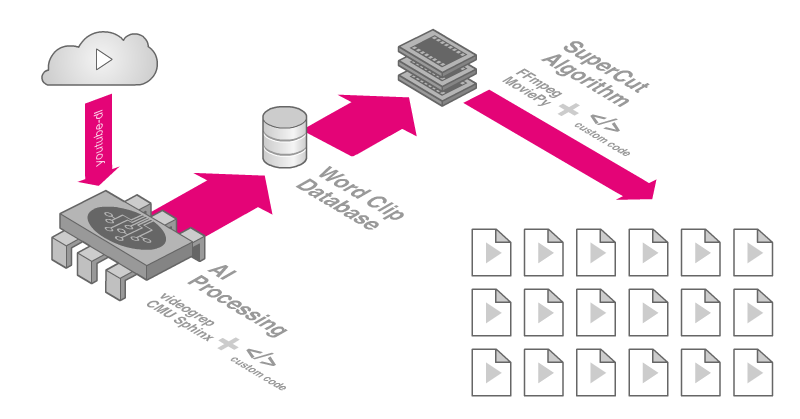
The resulting software pipeline was a testament to the strength of open-source technologies and the state of machine learning. It consisted of a custom JavaScript application which uses the YouTube Data API and youtube-dl to source and download footage respectively. Next, videogrep and CMU Sphinx are used to transcribe and cut individual word clips. Custom python code and ffmpeg then process the final supercuts, and a series of custom node.js utilities helped to address various challenges along the way. The final command-line tool could generate seemingly infinite variations of the supercut from nearly a million word clips sourced from thousands of hours of footage.
A few Media mentions:
NME,
DigitalSpy,
Engadget